|
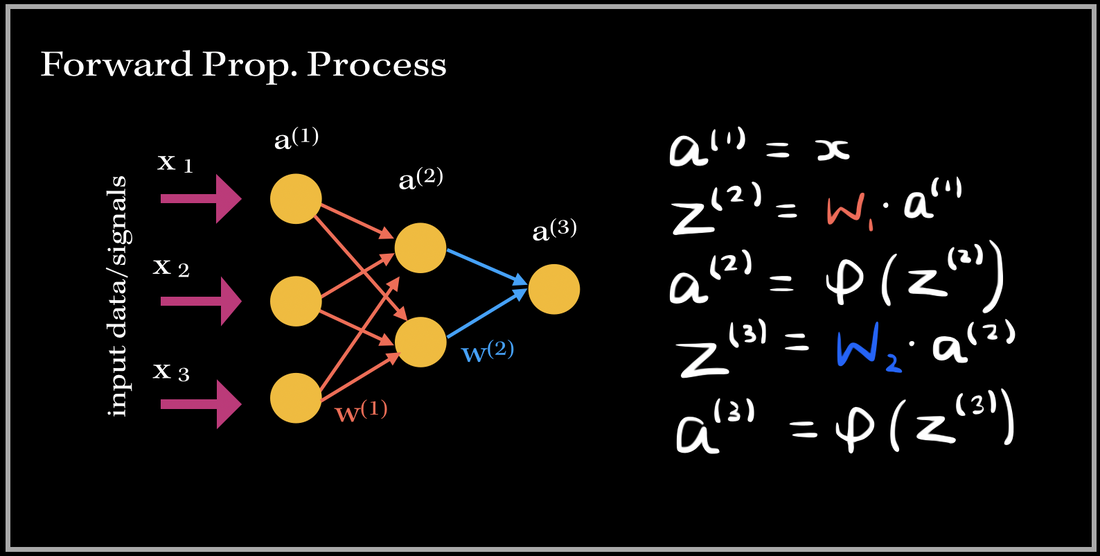
I've always wondered as to what happens in the 'backend' of the training process in Neural Networks. The training process is essentially the 'meat' of the model; without efficient and effective training the model will not be able to accurately predict/classify or accomplish a task with newly unseen data. Neural Networks have always been held as a very useful system in prediction analysis, recommendation engines, modeling and a lot more; it is because has the ability to extract complex patterns and relationships between the input and output data. This is because of the numerous layers of neural networks, that make the machine learning 'deep'. So what does the training process of this neurological-biological computer model-system (aka neural network) look like? It consists of two phases: 1). Forward Propagation and 2). Back propagation. Once we have preprocessed the dataset (such as normalization, reshaping your data to a specific dimension..etc.), we are ready for the training process. We first forward propagate our data—meaning we feed in the inputs into our built neural network. 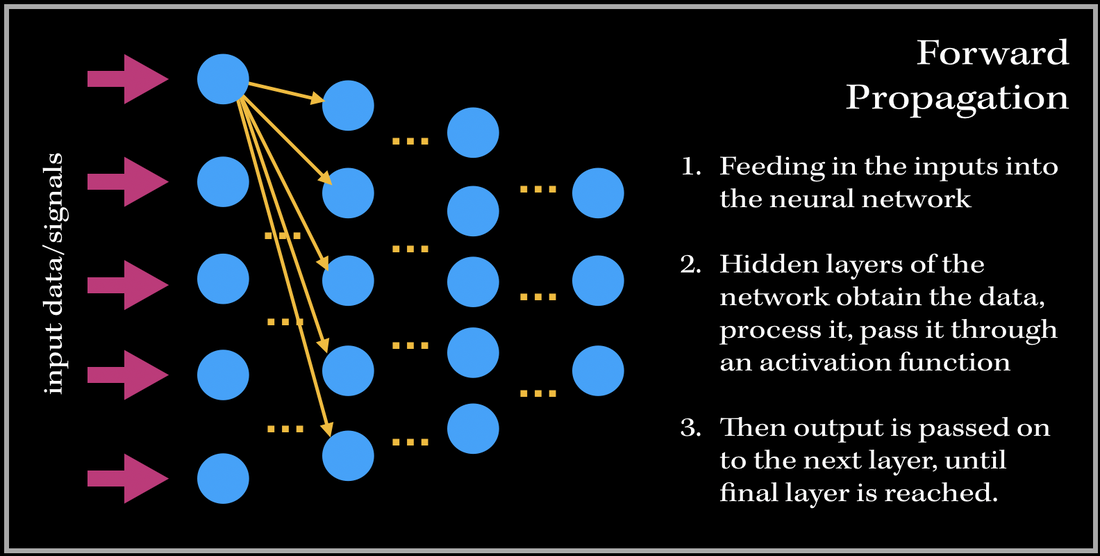 I like to think of forward propagation consisting of three simple steps: 1) Send in a data point (or a subset of training data points), 2) the layers obtain the data, process it (by computing the dot product), and pass it into some non-linear activation function (ReLU, Sigmoid, Leaky ReLU), 3). Output from previous layer is passed to next layer. The process continues until we have reached the final layer. Before we get into the deep math, let's define some variables. These definitions are applied to every example in this blog post!
 SO, what happens after we have passed an instance of our training dataset to the network? Back PropagationThis is where back propagation comes in. Back-propagation is essentially an algorithm used in training neural networks and is used to improve the model's performance/accuracy. Our neural network will update its parameters (weights and biases) once every time a number of samples is passed into the network (aka: an epoch in gradient descent algorithm). Basically, in Back Propagation, we need to adjust the weight parameters based on our loss function — whether it be calculating the mean squared loss, absolute mean loss or any other loss function we use — and our updated weights must head towards the right direction (in reducing the loss). Let's look at an example, and focus on one specific output neuron in a neural network model. We first pass in our input training data, and get a single output neuron of 0.5. However, the specific target value for the neuron is 1.0, so the cost function computes the error, and our optimizer uses the loss to back-propagate and change the weights to minimize the loss. This is why the process is at times called back-propagation of errors, since updates to one layer impact the next layer, and because of this backwards calculation technique, we are preventing redundant calculations. 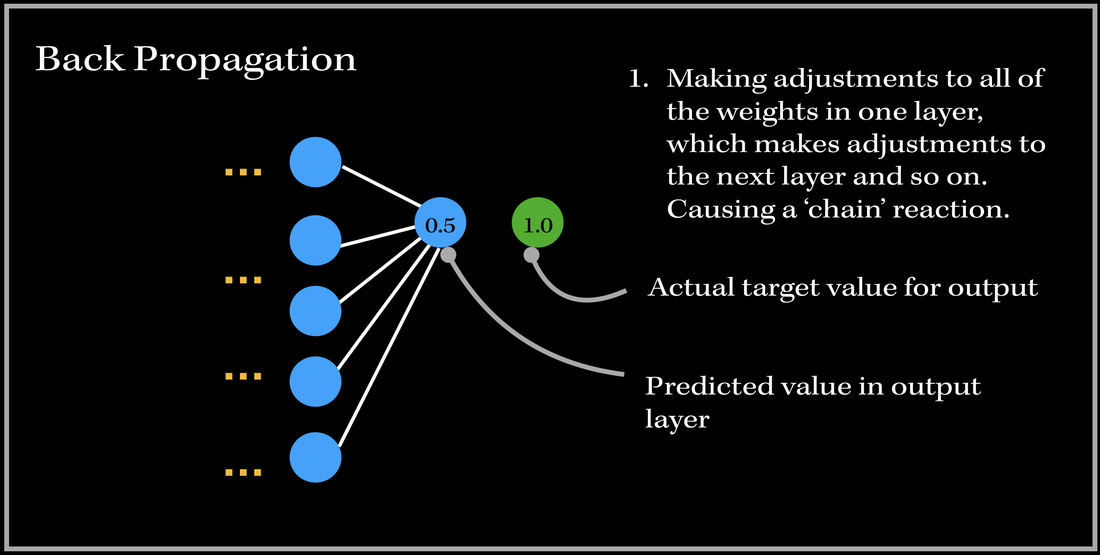 To do this, we need to figure out how much of an impact does a certain weight (between a node from one layer and a node from the previous layer) have on the cost function. Does the weight have a very low impact (ie. the cost function doesn't drastically differentiate when the weight parameter changes), or does it have a very important contribution towards minimizing the loss? In order to find this out, we need to look into a very important operation: partial derivatives. The Process
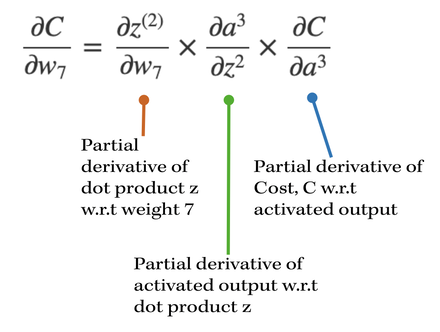
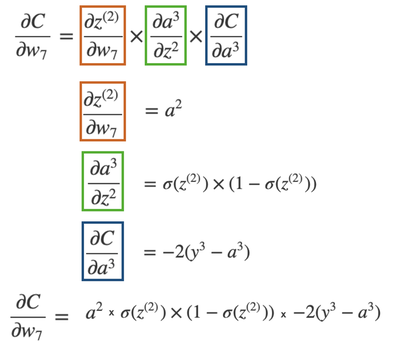
Let's go do a back propagation run through with an example. Say we had a neural network with 3 input neurons, 2 neurons in the hidden layer, and 1 output neuron. 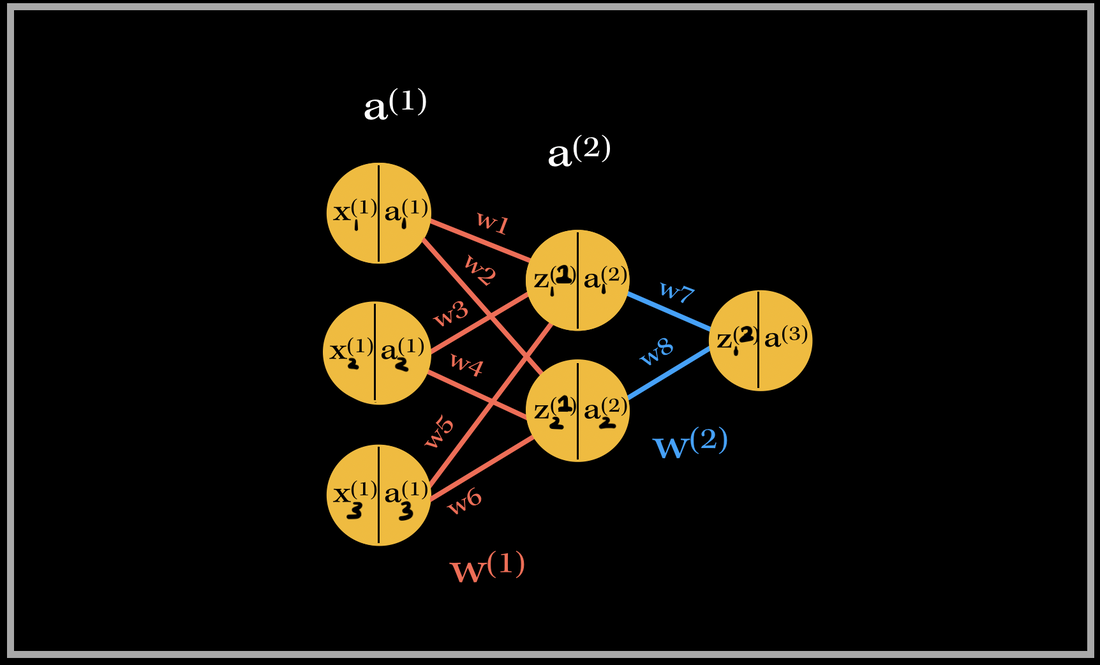 Neural Network Model with denoted weights, activation values, and dot product values (in neurons) NOTE: In each neuron, the number on the left side is the input, and number on the right side is the activated input (passed through activation sigmoid). Back-propagation of the output layerThe total number of weights in this network is 8. We have 6 weights in the first layer and 2 weights in the second layer. Let's first focus on the computing the partial derivative of the cost with respect to one of the weights contributing towards the output neuron: w7. What is the partial derivative of C, the cost, w.r.t to w7, weight 7?
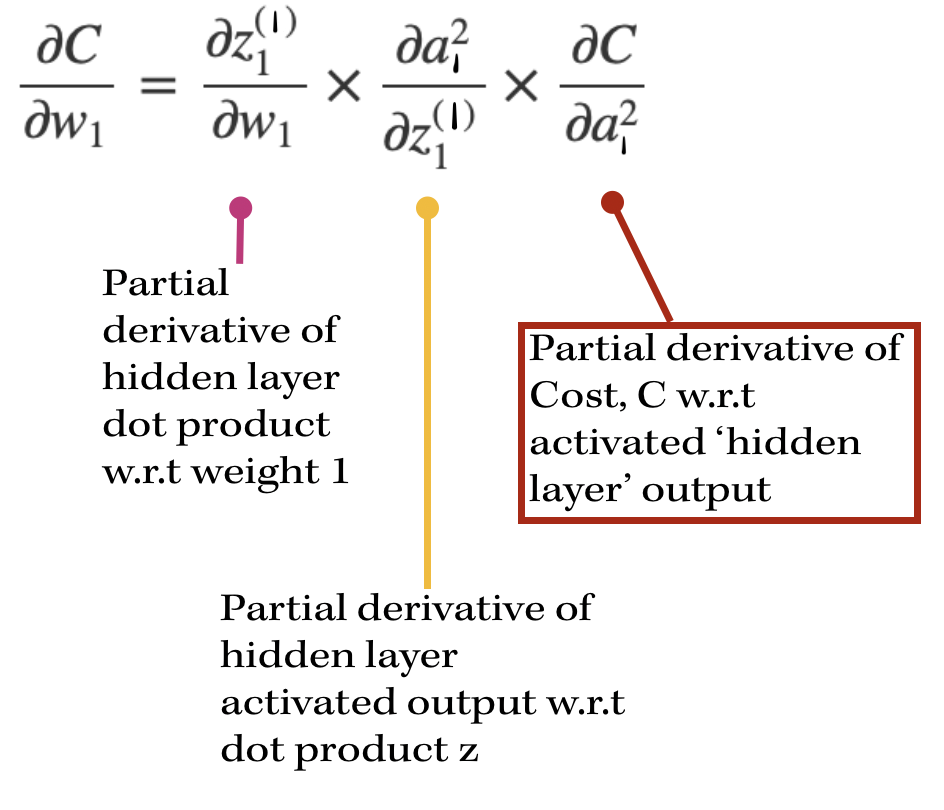
Back-propagation of a hidden layerNow, let's back propagate to the first layer, and compute the gradient of weight 1, w1. The partial derivatives will look slightly different this time, since the cost isn't directly associated with the hidden layer outputs. With our focus on weight 1, the partial derivative of the cost w.r.t w1 is going to depend on the partial derivative of the cost w.r.t. the output of the hidden layer neuron. This will look like:
So in order to find the partial derivative with respect to the hidden layer output, we need to include the next layer's weight's contribution towards the cost. Therefore, we need to include the weights that are being multiplied by the activation output of the particular hidden layer's neuron. In this case, it's only one weight: w7. However, if there are multiple weights contributing, we would have to add them to the equation as well.
The partial derivative of the Cost w.r.t. the hidden layer activation is broken down again into three parts: 1). First starting from the cost w.r.t to the output activation, then 2). the activation w.r.t the output dot product, 3). then the output dot product w.r.t. hidden layer activation. As you can see there are many terms being repeated in finding the updates for both weights 1 and 7!! This basically sums up finding the gradient of the network. As you can see, it requires lots of computation and derivatives!! Imagine the workload of computing the gradient vector of bigger neural networks with millions of parameters and neurons--backward propagation does this by using the previous layer's computations to compute the updates for the next layers! It's an amazing feat! Back propagating in action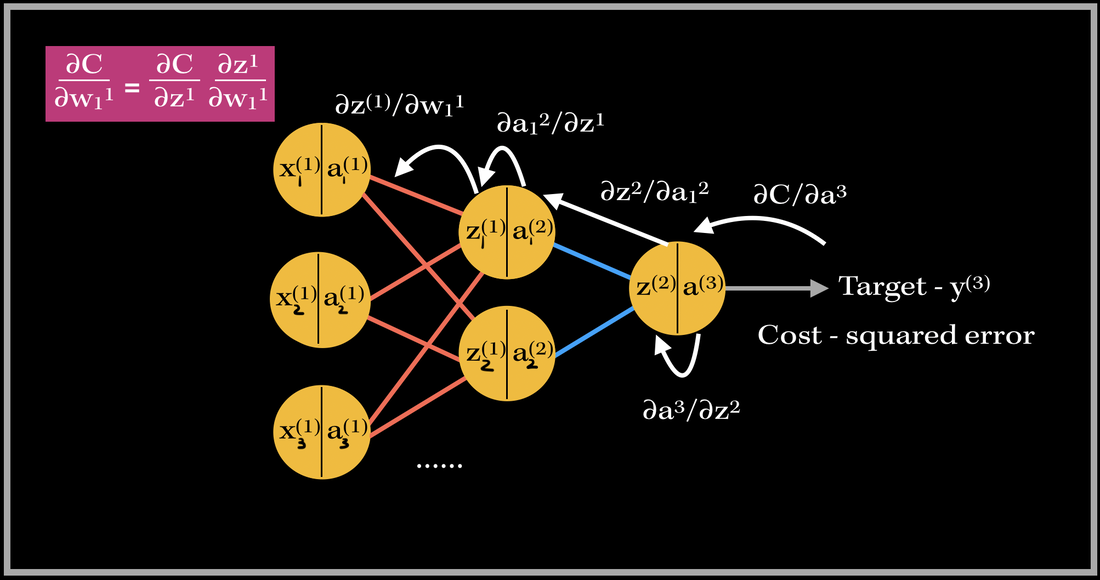 Back propagation in action for weight 1. So this is where 'back propagating the errors' comes into play. The image above is an example of back propagation in action for weight 1. The previous partial derivatives are reflected in the update value for weight 1. The white arrows show the path of each derivative computation for weight 1's update.
This same process occurs for every weight in the network during back propagation. Back Prop is one of the most important parts in training supervised learning neural network models! :)
1 Comment
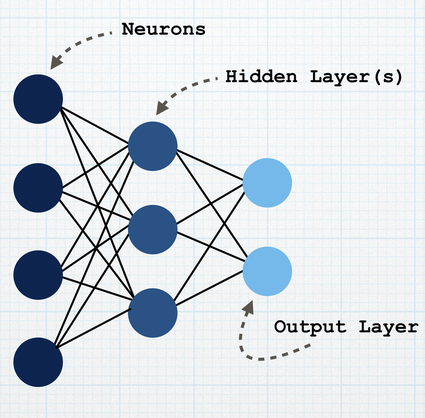
***During the COVID-19 pandemic, it is important to remember not to panic, but to be precautious and stay safe. Please be sure to wash your hands thoroughly and properly, and practice social distancing at this time.*** Stay safe we can fight this ❤️ With the global pandemic increasing in scale and spreading quickly, it is very important for us to stay precautious, safe, and healthy. There needs to be an efficient way to make diagnosis times easier for doctors, nurses and medical professionals so that they can focus on treatment immediately, and one certain way is to use neural networks and deep learning to find a solution to this problem for us. About Neural NetsA Neural Network, or a Neural "Net", is a deep learning model which sort of acts like a real biological neural network. It is a system which learns a specific pattern by taking in examples, without being explicitly programmed to achieve the task. To build or implement a neural network through code (for example, Python), there are 4 steps to essentially follow: 1. Set the architecture of the model , 2. Compiling the model, 3. Fitting the model, 4. Predicting with the model. Before we delve into the four step process, lets take a look at how a neural network looks like: A neural network is composed on neurons (or nodes) and layers.
Forward and Back PropagationThis process is called forward propagation. The neural network makes predictions using the process of forward propagation. It takes in the input feature values as the input layer, maps the target values at the output layer, and performs the computations, until it leads to some output target value. Now, what if the network makes a prediction which is not accurate? What if the prediction the network makes is far from the actual value? This is where we need to update the weights so that the values are more closer and accurate with the actual target values. In order to achieve this, the network goes backwards from the output layer to the previous hidden layer(s) (all the way up to the input layer) and updates the weights using an optimizer so that the next predictions are more accurate. An optimizer is essentially an algorithm which helps us minimize the error of the predicted vs the actual target value. Every time we train our network, our goal is to minimize the loss so that the neural network can accurately predict the next set of data. When we plot our losses for all possible weights, we have to ensure our loss is at its minimum value. In order to find the minimum value loss, we need to look for the minima of the function, or where the slope is 0. The optimizer updates the weights by using a learning rate, which we use to change the weight accordingly. Four Step ProcessNeural networks can be used to solve many many classification or regression problems such as Image Classification, character recognition, and natural language processing. But how do you implement a neural network to solve a problem? These are the 4 steps: To build a neural network, we first set the whole architecture or the structure of the neural network. We first import the important libraries we need to build this network. The main library we require is the keras library, which is a neural network library in Python.
Importing important libraries...
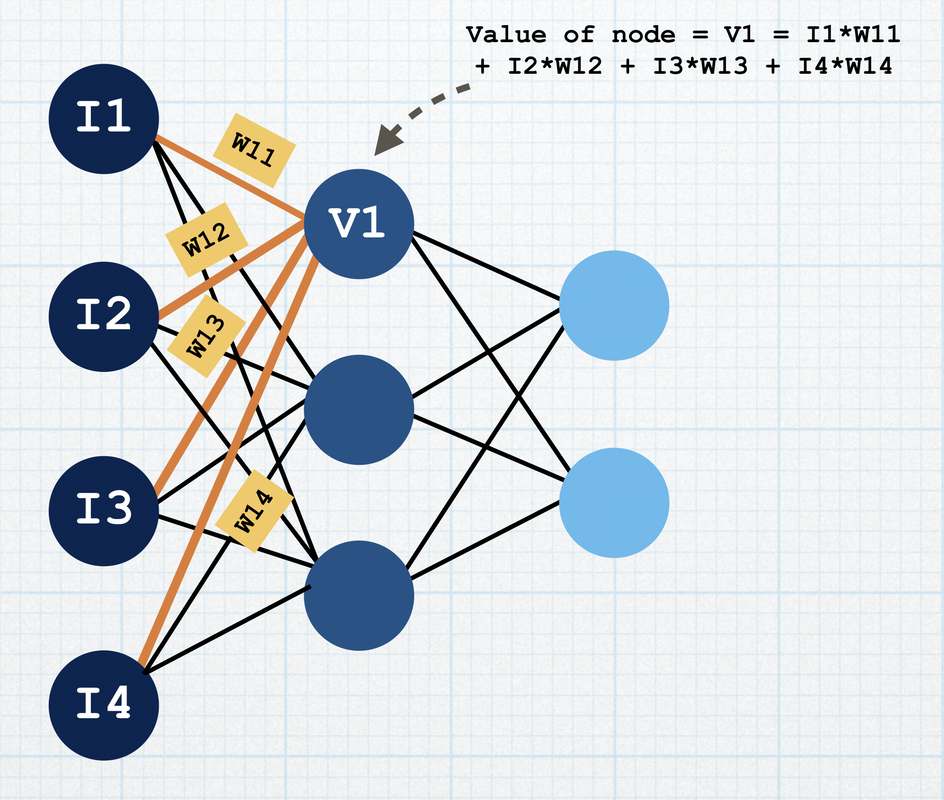
In this step, you read in the input training dataset. To do this you use the read_csv function from the pandas library (another library in Python for datasets). We then use the Sequential model API in the keras library to build and instantiate the model. A sequential model is pretty self-explanatory; every layer only has connections to the layer coming after it. To add a layer to the model, you can use the .add(Dense()) to specify the layer. There is something called an activation function, which defines the value of a node given the weights and inputs. The relu activation function states that if the value is positive, it's just the value, else the value is 0. When we define our first layer, we also need to add our input shape, which represents how many columns or feature inputs the dataset has. The next step is to compile the model, where we specify the optimizer. The optimizer modifies the weights as throughout the training process, so that the predictions are closer to the actual target. To compile the model, you need to first specify your optimizer (there are many kinds, for example, Adam optimizer, and the SGD - Stochastic Gradient Descent optimizer) and the loss function (for example MSE - mean squared error). The loss function is a way to calculate the error between the predicted and actual values. For MSE, we basically square all of the errors of the predicted/actual values, and take the average of all of them.
Compiling model....
The third step is to fit the model with your dataset!! This is a very fun part: you basically fit the X and y dataset portions (which are the input/features and the targets respectively). This will fit the dataset into the model you have created.
Fitting the model
The last step is to predict values for your testing set. This is to test the model's accuracy with data is hasn't seen before. To do this, you would:
Predicting for testing set
Deep Learning and COVID-19Deep Learning algorithms and neural networks can help us detect infections from CT scans. This can improve the process of diagnosis, and we can also use machine learning to learn from all sorts of data: whether it be the geographically impact of COVID-19, or other external influences of the virus. Stay safe, healthy and wish y'all loads of happiness!!!! We got this! ❤️ Ok so today my professor decided to tell us a Halloween joke, and I thought it was the funniest thing ever: "What is the circumference of a jack-o-lantern divided by its diameter??" Pumpkin pi !!!!!!!!!!!! lol, i thought it was funny!!!!!!!!!!!! (its ok if you didn't) :) happy halloween lol i didn't really dress up like anything because I barely even have time to fully get ready in the morning, but if "a student who is heading over to class to take her exam in matrices" counts as a costume, then yeah sure, I did "dress up". Ok so I was reading this article a while ago about implementing AI algorithms in hardware chips, and I was like WOW?!!! That sounds VERY VERY cool and interesting, and can be valuable and have a positive impact in so many other industries. So recently, deep learning and machine learning have become pretty big things. This is because it can be used in practically any context. However, it also requires an intensive amount of algorithms, and complex processes. We need efficient tools to accelerate the tasks of Artificial Intelligence. But what is deep learning, machine learning, artificial intelligence? I feel like these are like the main words everyone using lol, but we need to understand why we use these types of "learnings". We use ML (abbreviation for machine learning cuz I've already used it 100 times lol) to make a machine intelligent without explicitly programming it. intro to machine learning, deep learningSo lets start with machine learning. It is one of the new technologies that is out right now. If you haven't heard of the term, thats totally cool! It is a pretty new thing, and many industries (not even tech related btw) are using machine learning to efficiently do human tasks. Machine Learning is a branch of study all about training a machine (computer for example) to do complete tasks without explicitly programming it. Image classification is an excellent example to explain machine learning. If you want a computer to classify a specific image as a cat, you would train your computer to learn certain features of the cat that are distinguishable from another animal. Another example is being able to detect if your email is spam or not. So you basically need to feed in large amounts of data to your machine learning model for it to learn patterns from that data, and accurately predict future datasets. This requires lots of algorithms and processes, which is where deep learning comes into play. Deep Learning uses an algorithm called neural networks to process, classify and make predictions on data sets. In order to get accurate results, you need LOTS of data. When you need more datasets, its gonna take a longer time to efficiently analyze the data. This is where accelerating the 'analysis' of data comes into play: and hardware processors can take care of that. Making a processor/microcontroller do many "intelligent" things sounds like such an amazing feat. In order to run such complex neural networks and process so much data and information, you need powerful and efficient processors. But what processors do we use? Which ones are the most efficient? what is a CPU?A CPU is basically the brain of a computer: the Central Processing Unit. It essentially executes and performs all of the instructions (in a program, software, application..etc.) such as logical operations, arithmetic, and I/O (input/output - communication between devices). A long time ago, CPUs were built with one core - which means they could only perform one task at a time. However, due to advancements in technology, we can now build multi-core CPUs - which means they are able to perform couple more tasks at a time.
CPUs vs. GPUsA GPU is called a Graphical Processing Unit, and its designed differently compared to the CPU. A GPU has many, many more cores, and they are much smaller compared to the ones in the CPU. The cores are designed like this so that parallel, but simple computation (since the cores are smaller) can be performed, and many tasks can my completed simultaneously. GPUs are used a lot in the gaming industry, for image processing and computer graphics (hence the term "Graphics Processing Unit"). In general, the design of the GPU makes algorithms more efficient, compared to the design of a CPU. A great example of the development of GPUs is NVIDIA's platform called CUDA! NVIDIA's CUDA computing platform uses GPUs to make algorithms and computing more efficient and fast for developers.
....and which one is better?This totally totally depends on what situation you are working on. If you are working with deep learning and ML models, chances are that GPUs are a better fit. This is because ML requires a lot of matrix math related calculations, which can be really effective if done in parallel. CPUs are better for more complex but sequential, step by step math or logical problems. Also, there is a huge cost factor too. GPUs generally cost more than CPUs, so there are multiple factors to consider before coming to a decision.
|
Archives
December 2020
Topics
All
|


 RSS Feed
RSS Feed
