|
I've always wondered as to how the power grid works, and distributes electric power to our homes and buildings for heating, lighting, cooking, and so much more! Power is an extremely important source that meets our needs for everyday tasks. Therefore, after lots of researching, I wanted to present some important processes and steps that occur in power distribution grid systems to better understand how the grid works in general! Lets go: Electric power is delivered to our homes via the power grid (aka electric grid). Well, what exactly does 'power grid' mean? The power grid is a complex system that supplies electricity from the power producers (generators) to homes, businesses, and buildings (the consumers). The system is comprised of stations, substations and transmission/distribution lines. The power grid is made up of three main components:
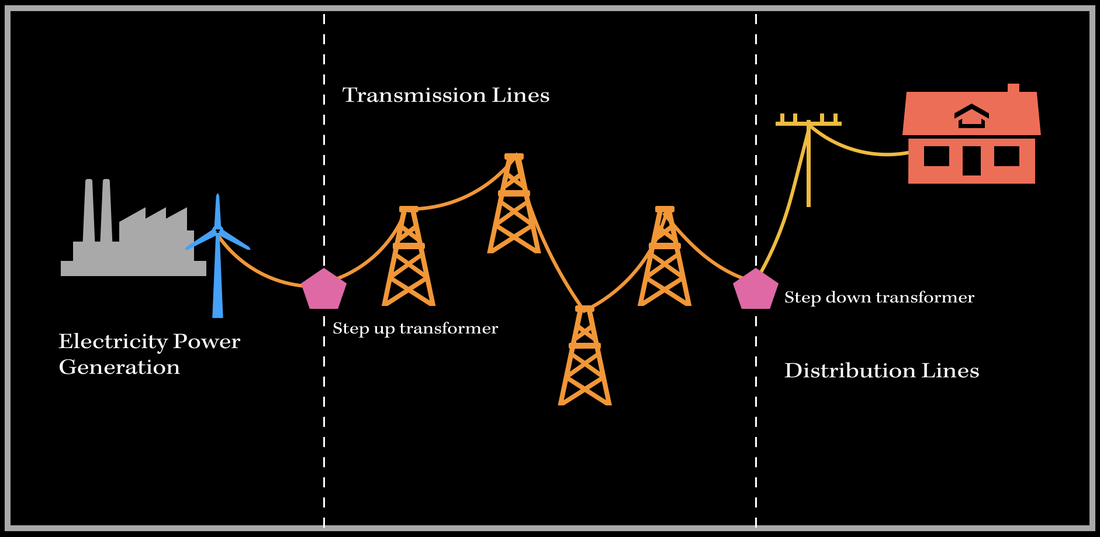 A simple representation of the power grid system. 1. Power GenerationIn order to supply and distribute power, we need to be able to generate it first. The power generation step uses different forms of energy sources to produce electricity! The first law of thermodynamics says "Energy cannot be created or destroyed. It can only be transformed or converted frome one source to another." Therefore, we need to transform one source of energy into electric energy to generate electrical power! One way to generate electricity is to use turbines and generators to convert kinetic energy to electrical energy. A turbine is a rotational device that uses a source's kinetic energy for rotational motion. A source is used to turn the turbine, which in turn rotates the coil of copper wires in a magnetic field. This is in the electric generator. From Michael Faraday's laws, if you move a coil of copper wire in a magentic field, an electric current is produced! The faster the coil of wire moves, the more electric energy is produced! This mechanical movement produces the electricity we need to distribute across hundreds and thousands of miles! Any source can be used to move the turbine; for instance, wind, gas, steam, or hydroelectric turbines exist to generate electricity. There are many different forms of electricity generation, from petroleum, nuclear, renewable, natural gas to coal! The following figure shows a statistic from the years of 1950-2019, and displays the number of kilowatthours produced changing over time. 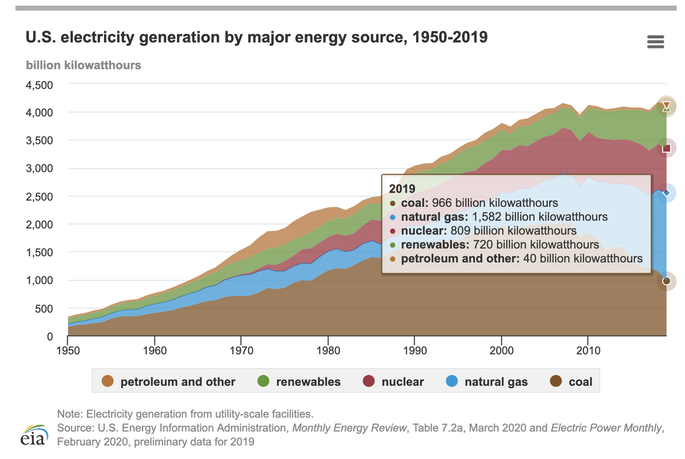 From the U.S. Energy Information Administration, https://www.eia.gov/energyexplained/electricity/electricity-in-the-us.php 2. Transmission LinesOnce the electricity is produced, its time to transmit the power to our homes. Before we get to that step, we need to ensure that the electrical energy loss is minimized as the electric current travels over long distances. The higher the current, the more energy loss occurs due to the heating in the wire. Therefore, we need some way to reduce the current, and at the same time, maintain the power.  As per this equation, since power is constant, by increasing the voltage, the current reduces. Therefore, there needs to be some sort of mechanism to increase the voltage, therefore reducing the current. This is done by a step-up transformer. A step-up transformer increases the voltage, while a step-down transformer decreases the voltage. Once the step-up transformer has increased the voltage, the power is transmitted to different substations and distribution centers (electric facilities) via transmission lines. Transmission lines are used to carry and transmit the power over long distances. 3. Distribution Lines
4. Power to safely use at homeThe final step of this system are homes, buildings and businesses receiving the power safely at an appropriate voltage level for use. The electricity reaches our homes' by passing through the service panel, where it connects to all of the appliances and loads in the home! :) This is meant to be a quick and short intro on power grids. I know power is something we take for granted, and I think learning about how the system works to meet our needs is an extremely important thing! :) SourcesSome fascinating resources that helped me out during research!
1 Comment
sshhhhhhh. Lets talk about this fancy little term called "ssh". What exactly is ssh and what does it do? ssh stands for Secure Shell, and it is essentially a protocol used in order for two devices to talk to each other or communicate with each other. It is called "secure shell" because this protocol uses strong encryption to allow safe communication between a client and a server. So for example, you can basically connect to a computer (server) remotely by using this protocol. It is used for logging into computers over the internet, and to communicate with them (execute commands) to transfer data (such as files, or important information)--although this is just one function out of many other uses!! Every time you "ssh" into something, you are accessing that computer/server over the network. You can connect to a server via a particular terminal (like Terminal in macOS, PuTTY..etc.) and the SSH protocol!! The procedures usually vary from terminal to terminal but if you type in ssh into any particular terminal, it should give you a list of options (flags) you can use to connect to a server. These options or flags specify certain restrictions that the protocol needs to apply. For example the ssh -4 options enables ssh to use only IPv4 addresses. The -6 flag uses IPv6 addresses. The -i flag tells ssh that there is an "identity file" (such as a private key) which authenticates the user to communicate with the server.  When I type in the "ssh" command into Terminal (macOS) you can see a list of flags you can use to connect to a particular server... How does it work??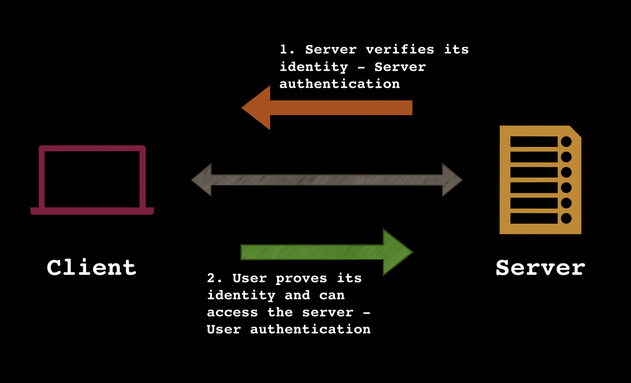 When you establish a connection to a remote server, by using the ssh protocol (typing the command into the terminal and setting the destination server host name), there are 2 steps that help the client/server verify and prove their identity to each other. The client needs to make sure its accessing the right ssh server, therefore, when the client initiates a connection with the server, the server verifies its identity to the client. Then, the user/client verifies that they are authorized to access the server (User authentication). This is obviously a very high level approach of understanding ssh, there are many many tiny details the ssh protocol involves (such as public key authentication). I'll get into that more on later, but for now, GOOD LUCK :)
 Ok so first off, please excuse this very cringe-worthy border, but I couldn't be more excited to announce that I'll be starting my very own building series!!! So essentially, every week, I'm going to be filming short tutorial like videos on building cool projects (such as a digital to analog converter, robots to help with your day-to-day activities, or even programming projects..etc.) and posting them on the "#buildwithRushi" page (on the menu). The first "episode" will be out on the 25th of April, and I'll most likely be continuing to post a new tutorial every Saturday! But it'll be very very fun!! Hope y'all enjoy it and be sure to look out for updates on the page every Saturday! I'm providing a little sneak peak of what I'll be building on this post, but I'll be explaining and demo-ing it using my Arduino UNO board on the buildwithRushi page! Check it out then!! Ok anyways, lets get back to business. Lately, I have been really interested in sound systems. Not just because I have been listening to music all day lol, but because I really really want to know what is behind a speaker, and how it converts digital bits of information (like 0s and 1s) to analog waves. Its just insane to think about how some sort of electronic system can transform bits of information to the cool sounds we heard through our headphones. How does this happen tho? It is all because of a Digital to Analog converter, or a DAC. What is a Digital to Analog Converter?A digital to analog converter is a system where a digital signal is converted to an analog signal. DACs are found in sound systems such as CD players, or sound cards (to hear your computer's audio). Audio signals are stored in digital form (MP3, for example), and a DAC converts it into an analog signal for us to hear it.
Now, there was a time where we actually didn't really need a DAC. This was when the analog signals were created when the needle of the record player made contact with the record grooves. It would cause an electric analog signal, which was then transmitted to the speaker, so we could hear it. How does a DAC work?
I'll get into more details about DAC functionalities next Saturday, April 25th! Lets goo! Stay safe, stay home, contribute, and wish you happiness and peace!
Fun fact: Today is the first palindrome date in 909 years: 02/02/2020! The Internet is such a powerful force; it allows us to communicate/recieve information from different parts of the world! It's just insane and amazing to visualize the different aspects of networking; and how the Internet forever revolutionized our way of seeking information! It all has to do with the hyped up term "Internet of Things". The term Internet of Things, or IoT, describes a system of connected devices, appliances, vehicles and digital technologies (and other "things") that can send data/information without human-to-human or human-to-device interactions. So instead of me walking up to another individual/device in another country to send some info, I can do that using the Internet. WiFi vs. InternetI have always used the words WiFi and Internet interchangeably, you don't even know so many times! But there is a slight difference between these terms. WiFi essentially stands for "wireless networks", and the Internet is "interconnected networks". There was a point in time where devices could only be connected through cables to connect from one device to another. It wasn't too efficient, however, since there was a location limit, and it was kinda inconvenient if you wanted to connect more devices. So essentially what WiFi does is it allows you to connect with devices without cables, in a local area network (like your homes, for example). It does this by using a router, which routes information (in small packets of info) from one device to another. The wireless local network is completely separate from the Internet. The Internet is a wide area network, or WAN. It is a huge network which links devices and computers across the world.  How is the information transmitted?So first off, every device on the Internet has some sort of unique identifier, for devices to recognize one another. This is called an IP address. Our laptops, phones, and servers (which are devices that manage/store information) have IP addresses. So how are these vast amounts of devices all connected globally, around the world? Well first off, this is a simple diagram of two devices are connected to the Internet:  Both of these devices will have unique IP addresses, and the Internet is basically the vast networks which data packets will route to until its destination is reached. So when you send information from your device to another device, the information is split into packets and is routed to the destination device via the Internet. But how exactly does this all work, and that to wirelessly? The computer needs to process the message, convert the text to signals, send it to the Internet, and the router near device 2 needs to convert the signals back into text. For this to be accomplished, there needs to be a protocol stack. Every device needs this, and this usually is in its operating system. Server being downWhen you are accessing a website, you are basically sending a HTTP protocol command to the web server in the Internet, to transmit the webpage (that's why websites start with http!!) Now you know when you were trying to access a website, and for some reason your web browser isn't processing the request. It often happens when the web server is down and under maintenance. These are some examples of when the server might be facing a technical problem:  Gateway time-out occurs when web server is communicating fast enough with other servers to process your request. Networking and the Internet is just a whole new world; there is so much more to explore!
HAPPY HOLIDAYS!!!!!! If I were put in a tough situation to choose between working in the hardware engineering industry or software, I would be inclined to say that I'm more of a hardware person. That being said, I've always loved to see the connections between both the software & hardware side of things, so it is a hard decision to make. To celebrate the importance of hardware, I've been wanting to actually explain what hardware components I collect (like RAM, motherboard, circuits, resistors, capacitors..etc.) from previous labs and assignments and explain the significance and importance of some of the most intriguing pieces!
RAM (Random Access Mememory)
Ethernet Adapter
I think the coolest part of collecting these pieces is the story behind them as well as learning about what actually goes into building these complex circuits. It's just so fascinating to learn so much out of just collecting random pieces of hardware!
I've always seen articles with titles like "Inside the mind of a <super smart person or celebrity>" or something along those lines, so I decided to incorporate some concepts of Linked Lists to this (hope you liked my reference to the cheesy titles lol). Whenever I think of Linked Lists, the first word that comes to my mind is "Linked"In, which I guess is a good starting point as to how Linked Lists actually work. Just like how users in LinkedIn have connections, Linked Lists have "nodes" that connect to each other as well. A linked list is a data structure which consists of a collection of nodes connected in an order. 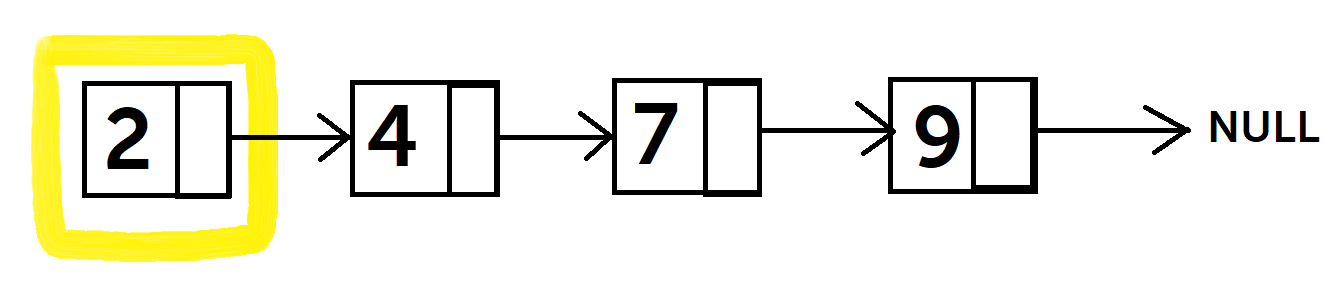 So basically every node (highlighted in yellow) consists of an int value (holding 2 in this case) and a pointer to the next node. What is a pointer? A pointer is essentially an address in memory. So this node also consists of an address which is the location of the next node. Note that a linked list does not have continuous memory like an array, so you DO NOT have direct access to elements. So, for example, if you would want to access the third element of an array, you would write "array[2]". However, for a linked list, you would have to traverse through the linked list until you reach the third element. This is because you need the previous node to find the location of the next node. That's why its called a linked list. Because the nodes are connected or "linked" to one another. Also, there is a NULL terminator in a linked list. So when you are traversing through your list and get to NULL, you know you've reached the end of your list. Implementing a Linked ListTo implement a Linked List, you can either create a class (for C++ Object Oriented) or a struct (for C, more low level). A struct is essentially a "record" of a group of variables with similar or different data types. It is stored as a chunk of memory. In C++, you can just create a simple Node class with the two variables, int data for the value and then the pointer. How would you write a method to insert a node at the end of a Linked List? You first need to traverse through the list until you reach the end (step 1), and then change the next pointer of the last node to the node you want to insert (step 2). NOTE: For C, you have to use malloc to allocate the Node in memory; for C++, you can just use the new keyword to create an instance of the Node class. Example of Implementation in C and C++
When storing data on the "cloud" became a super big thing, I never really understood what the "cloud" meant. Was it just a supercomputer which handled massive amounts of data from companies, individuals, and other entities? Or was it more than that? The term 'cloud computing' refers to the ability to offer many services--such as storing data, servers, networking, and intelligence--over the cloud or Internet. Cloud Computing is literally one of the most BIGGEST services ever. Many companies, such as the Amazon Web Services (AWS) and Microsoft Azure offer cloud computing support mainly in order to handle and store data, and offer software applications. but first, what is the cloud?Before diving deep into cloud computing, we should first learn about what cloud is. What does the term "cloud" refer to? It would be really cute if it were an actual cloud lol, but its actually not. I know, the term is very misleading.  The cloud is essentially a bunch or "network" of servers. What does this mean? A server is a computer device which stores data, and offers support for other software programs or devices called clients. An example of a cloud service is Office 365 or Google Drive. So whenever you are storing your data or information in a cloud service, you are storing it in the cloud, which basically leads to storing it in a physical server. So this is how communication between a client (aka your device, or applications in your device) and a server occurs. It is known as the client-server model. big data and cloud computingNow, we know that data is all around us. For companies, every day, and every second of the day, some amount of data is generated. There is basically too much data to handle. So many companies have too much data to handle and store. This is known as big data. How do you store large amounts of data, and how can you handle, cleanse and protect it? These companies can store it in their own data centers or servers, but it requires a lot of effort and cost. Cloud Computing services can take care of all of that. AWS and Azure are just a few of the services offered to protect, handle, and store data from other companies or individuals. So essentially, other companies would buy the service, and pay per month, for the cloud computing service to store, handle, and protect the company's data in their servers. These are just some of the few services offered from AWS and Azure. There are many more. potential risks in cloud computingNow, all of this sounds very good. Companies with vast amounts of data can go to a cloud computing service and purchase their plan in order to store all of their data in the service's servers. However, there are some potential risks. Privacy is a huge concern for these companies. They are basically trusting the cloud computing services to protect their data and not leaking it to other competitors and companies. There will defintely be mutual agreements about privacy between the companies and the services. But, privacy is still a concern, and the data in the servers and in the "cloud" needs to be secure, protected and monitored. Even though there are a few risks, cloud computing makes accessing data much faster and efficient. It is a great technological lead for this industry.
Honestly, this is probably one of the most hardest concepts for me to understand well, and when I was introduced to BSTs in my Software Design class, it was super hard for me to develop it into C or C++ code. I think understanding the basic algorithm or 'psuedocode' of a BST is a super important step when you have to translate a problem involving a BST structure into C/C++ code. so, what is a BST?A BST, or Binary Search Tree, is a tree data structure where every node (every circle in the diagram) has at most two child nodes: a left child node and a right child node. The left node (and subtree) is smaller than the parent node value, and the right node (and subtree) is larger than the parent node value. 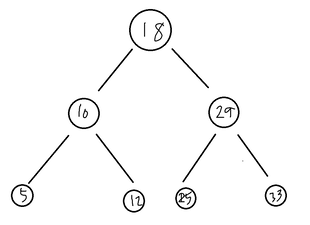 Every node doesn't have to have two children nodes; it could just have one node, with the other node pointing to NULL (meaning no value is stored in the node - so its not being used). A BST is represented by the pointer (address) to the topmost node, which is also called the root node. Every node has three different parts: the data value of the node, a pointer to the left node, and a pointer to the right node. We declare a node structure using struct function in C. To declare a node structure, we have the value of the node (usually a number, but can be any data type), the left node pointer (pointer to the left child of the parent node), and the right node pointer (pointer to the right child of the parent node). Note: when I say pointer, I am talking about a variable storing the address of the node (right/left). Declaring a Node Structure in C
So now that we know how a BST is structured, why do we even need it? If we need to store a bunch of random int data types, can't we just use an array of int types? We can most definetely use an array, however, for some tasks, the BST is super effective and efficient in terms of time complexity (how long it takes for the program to run). For example, when you are trying to sort elements in a particular order, the BST is very efficient since the elements are already sorted in a tree format. (right node is always greater than parent node and left node is always smaller than parent node). Therefore, it has an efficient algorithm, compared to arrays. algorithms with BSTs!!First, lets go through the search algorithm in a BST. How would you search an element in a BST? What if the element already exists in the BST? What if it doesn't exist? The easiest way to search for an element in a BST is to implement this recursively (meaning the program just calls itself again and again, until it reaches the base case). Check out the algorithm- this was based off of the geeks for geeks BST search set 1: https://www.geeksforgeeks.org/binary-search-tree-set-1-search-and-insertion/ In this search BST algorithm, if the output was a NULL node, then the program was not successful in finding the node with the element value. If it didn't return NULL, and it returned an actual existing node, it means it did find a value matching with the element. Lets now attempt an insert algorithm in a BST. How would we insert an element in a BST? Where would we insert the element? When we insert an element in a BST, we actually have to create a new node in order to actually insert it into the tree. We would first have to traverse through the tree to figure out where the element needs to be inserted, and then we create a new node to insert in that location. Lets use a helper function (seperate function) to make a new node, so that its easier to call that in our main insertBST function. Check out the algorithm-- this algorithm was based off of the geeks for geeks BST insert set 1: https://www.geeksforgeeks.org/binary-search-tree-set-1-search-and-insertion/ We can also use a recursive method to insert a new element into the tree. It was kinda difficult for me to grasp this at first, so I had to draw out how the tree would look like as you call the function again and again, recursively. So the base case here is whether the root is NULL, and if it is then you insert a new node there because that's where the element should exist. This program is recursively, so in the end, the new node is assigned to the root->left, or root->right depending on the value of the element. This is how it's added to the tree. NOTE: For this algorithm, we are assuming that the element does not exist in the tree already.
I remember finding it super tricky to understand how to convert this hash table information to C code. There is a lot of confusion and trickiness when it comes to implementing hash tables in C, so I figured why not write about it! And trust me, once you get the idea, it becomes soooo interesting!!! You can also implement the Hash Table in C++ as well, with different classes. 1. hash functionSo first, we need to write a function to figure out where to place the key in the hash table. In this case lets say we have 10 slots in our hash table. The hash function can vary based on the formula of your choice, or the data type you are dealing with. What if we are trying to store char or string type keys? Hash Function
2. chainingThe next step of implementing hashing in C is to implement chaining. For this, we need to make a linked list. One way is to declare a Node structure with two variables: the value and the next Node. When we implement chaining in C, we must first decide how we are going to pass in the arguments. The insert function below takes in two parameters: Node **, which is a pointer to a Node pointer, and int el, which is the element to be inserted into the Hash Table. For this implementation in C, I'll be passing in the address of the slot in the Hash Table (based on the index). So if we are inserting the element 5, we will first do 5 % n to find the index, and then pass in the address of (&Hash[index]), which is a pointer to a node pointer. NOTE: the '&' is used in C as syntax for the address of something. 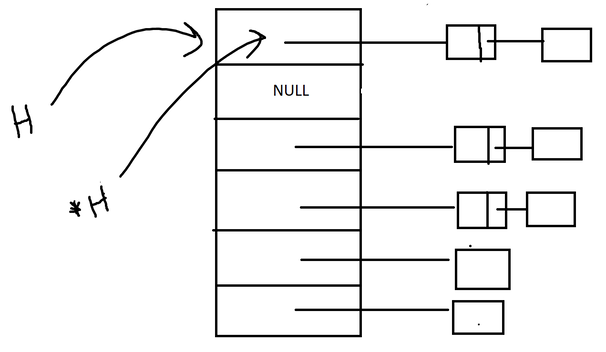 In this case, H, which is a pointer to a Node pointer, is the address of the first slot in the Hash Table. *H, which is dereferenced, is the address of the Node (which is in the slot). And in this example we are just focusing on the index 0 of the hash table. 3. putting it all togetherSo now, we obviously have to put it all together using a common main function to access the above functions. (chaining and indexing- using the hash function!)
One of those interesting yet tricky to translate to code concepts. Yup, another data structure. But hash tables are actually really cool and efficient to store data of any type (char, int, double..etc.) what is a hash table?Hash tables are another type of data structure, used to store, manipulate and search data (of any type) in a table format. It is used mainly because of its O(1) time complexity to store and access data. (very efficient and time effective) 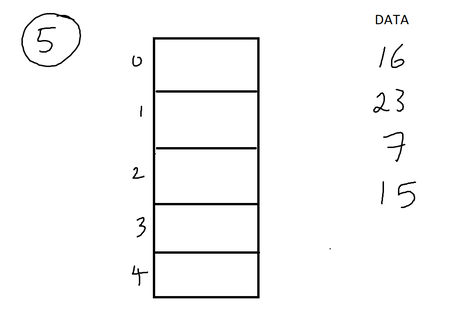 A hash table can have n number of elements, so it can basically be any number. In this case, I chose 5, just to start things easy, but it can also be 100, or 50, 60..etc. So basically the whole idea of a hash table is to store the given data (in this case ints) in every row of the table. In order to decide where to store which number, we derive a hash function. So what is a hash function? How do we decide which one to use? hash functionSo how would you derive your hash function to figure out where to place the keys (a fancy word for data values)? You can basically choose any hash function that works best. For instance, the hash function h(x) = x, basically maps the key to the index with the same value as key. So in that case this would look like: 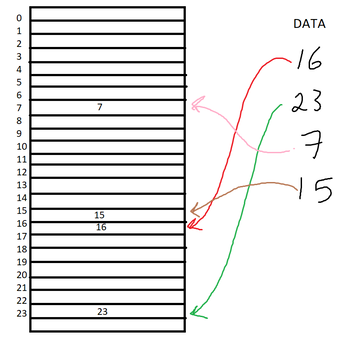 Obviously, there is a problem that arises with this hash function. You would need to allocate numerous spaces in the table, depending on the largest value in your given key data. For instance, if the largest value in the key data is a 23, then you would need to allocate 24 spaces (ranging from 0-23) in your hash table. This will lead to a lot of memory usage, and wasted memory usage for the slots that don't have keys in them. Ok, so then we need to figure out a hash function where you use up less memory but at the same time store the key values efficiently. We can use the modulus (%) function to help us. So, in our 5 slots example, we can set the hash function to be h(x) = x % n, where n is the number of slots, so it would be h(x) = x % 5. So it takes the key, does mod 5 to it, and places the key to the index that matches the result. So if we do 16 % 5 = 1, we get 1 and we place it at index 1. 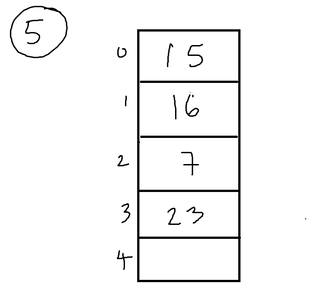 Ok, cool. So this works, and its efficient too since you are using less space for a certain number of elements. But what if I wanted to add another element, such as 33? So first, lets use the hash function on 33. 33 % 5 = 3. So we place it at index 3.....but WAIT. There is already a number at index 3. 23. This is known as collision. When we try to place a number to an index that is already taken by some other number. So how would we tackle such collision? What do we do now? the solution...chainingWhen we encounter such collision, we need to use an effective way to store both of those numbers at index 3 (23 and 33). So we use chaining. This time when creating the hash table, we create an array of pointers. When we insert an element into the hash table, we use the hash function to go the corresponding index, and then make new node so that the pointer in that index points to the node. So, gradually, as more elements are added, we basically make a linked list at every index. 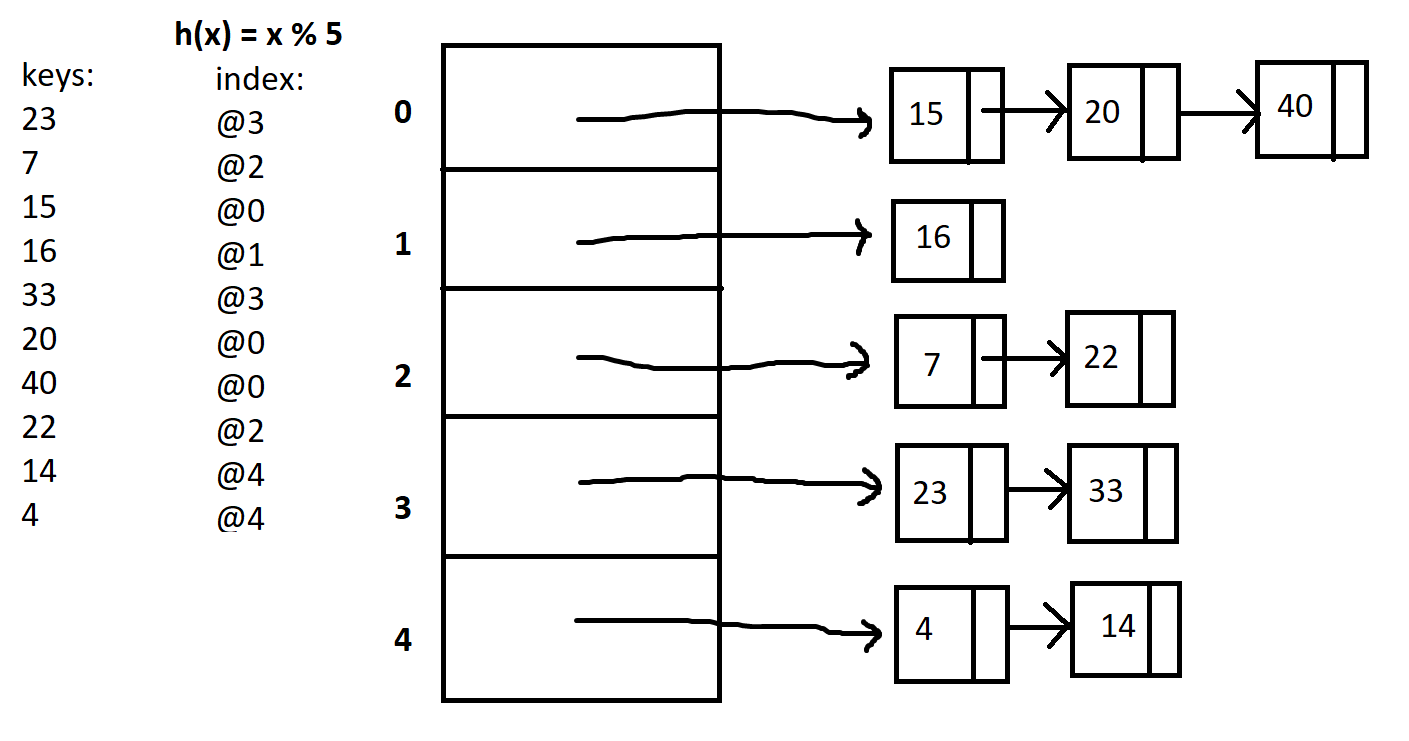 See how nice that looks? This is much more of an organized yet effective way of storing data. You basically use linked lists (another data structure which links one node - or piece of data - to another node until the last one points to NULL) inside of a table of pointers. You can easily access the element by implementing the hash function first, going to the index, and then finding the element. Now lets go to the hard part: converting all of this to C code.
|
Archives
March 2021
Topics
All
|






 RSS Feed
RSS Feed
