|
Honestly, this is probably one of the most hardest concepts for me to understand well, and when I was introduced to BSTs in my Software Design class, it was super hard for me to develop it into C or C++ code. I think understanding the basic algorithm or 'psuedocode' of a BST is a super important step when you have to translate a problem involving a BST structure into C/C++ code. so, what is a BST?A BST, or Binary Search Tree, is a tree data structure where every node (every circle in the diagram) has at most two child nodes: a left child node and a right child node. The left node (and subtree) is smaller than the parent node value, and the right node (and subtree) is larger than the parent node value. 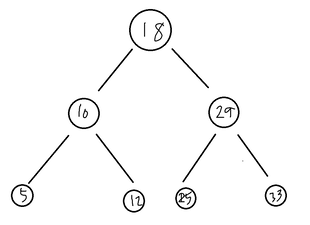 Every node doesn't have to have two children nodes; it could just have one node, with the other node pointing to NULL (meaning no value is stored in the node - so its not being used). A BST is represented by the pointer (address) to the topmost node, which is also called the root node. Every node has three different parts: the data value of the node, a pointer to the left node, and a pointer to the right node. We declare a node structure using struct function in C. To declare a node structure, we have the value of the node (usually a number, but can be any data type), the left node pointer (pointer to the left child of the parent node), and the right node pointer (pointer to the right child of the parent node). Note: when I say pointer, I am talking about a variable storing the address of the node (right/left). Declaring a Node Structure in C
So now that we know how a BST is structured, why do we even need it? If we need to store a bunch of random int data types, can't we just use an array of int types? We can most definetely use an array, however, for some tasks, the BST is super effective and efficient in terms of time complexity (how long it takes for the program to run). For example, when you are trying to sort elements in a particular order, the BST is very efficient since the elements are already sorted in a tree format. (right node is always greater than parent node and left node is always smaller than parent node). Therefore, it has an efficient algorithm, compared to arrays. algorithms with BSTs!!First, lets go through the search algorithm in a BST. How would you search an element in a BST? What if the element already exists in the BST? What if it doesn't exist? The easiest way to search for an element in a BST is to implement this recursively (meaning the program just calls itself again and again, until it reaches the base case). Check out the algorithm- this was based off of the geeks for geeks BST search set 1: https://www.geeksforgeeks.org/binary-search-tree-set-1-search-and-insertion/ In this search BST algorithm, if the output was a NULL node, then the program was not successful in finding the node with the element value. If it didn't return NULL, and it returned an actual existing node, it means it did find a value matching with the element. Lets now attempt an insert algorithm in a BST. How would we insert an element in a BST? Where would we insert the element? When we insert an element in a BST, we actually have to create a new node in order to actually insert it into the tree. We would first have to traverse through the tree to figure out where the element needs to be inserted, and then we create a new node to insert in that location. Lets use a helper function (seperate function) to make a new node, so that its easier to call that in our main insertBST function. Check out the algorithm-- this algorithm was based off of the geeks for geeks BST insert set 1: https://www.geeksforgeeks.org/binary-search-tree-set-1-search-and-insertion/ We can also use a recursive method to insert a new element into the tree. It was kinda difficult for me to grasp this at first, so I had to draw out how the tree would look like as you call the function again and again, recursively. So the base case here is whether the root is NULL, and if it is then you insert a new node there because that's where the element should exist. This program is recursively, so in the end, the new node is assigned to the root->left, or root->right depending on the value of the element. This is how it's added to the tree. NOTE: For this algorithm, we are assuming that the element does not exist in the tree already.
3 Comments
I remember finding it super tricky to understand how to convert this hash table information to C code. There is a lot of confusion and trickiness when it comes to implementing hash tables in C, so I figured why not write about it! And trust me, once you get the idea, it becomes soooo interesting!!! You can also implement the Hash Table in C++ as well, with different classes. 1. hash functionSo first, we need to write a function to figure out where to place the key in the hash table. In this case lets say we have 10 slots in our hash table. The hash function can vary based on the formula of your choice, or the data type you are dealing with. What if we are trying to store char or string type keys? Hash Function
2. chainingThe next step of implementing hashing in C is to implement chaining. For this, we need to make a linked list. One way is to declare a Node structure with two variables: the value and the next Node. When we implement chaining in C, we must first decide how we are going to pass in the arguments. The insert function below takes in two parameters: Node **, which is a pointer to a Node pointer, and int el, which is the element to be inserted into the Hash Table. For this implementation in C, I'll be passing in the address of the slot in the Hash Table (based on the index). So if we are inserting the element 5, we will first do 5 % n to find the index, and then pass in the address of (&Hash[index]), which is a pointer to a node pointer. NOTE: the '&' is used in C as syntax for the address of something. 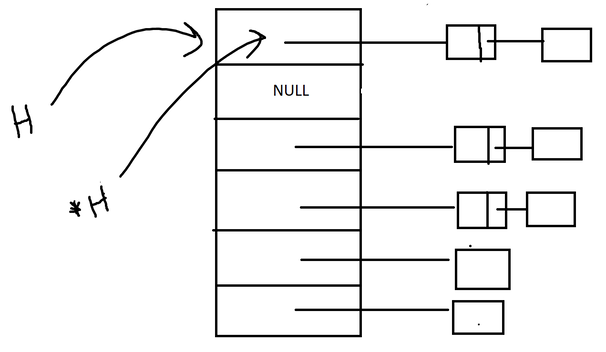 In this case, H, which is a pointer to a Node pointer, is the address of the first slot in the Hash Table. *H, which is dereferenced, is the address of the Node (which is in the slot). And in this example we are just focusing on the index 0 of the hash table. 3. putting it all togetherSo now, we obviously have to put it all together using a common main function to access the above functions. (chaining and indexing- using the hash function!)
One of those interesting yet tricky to translate to code concepts. Yup, another data structure. But hash tables are actually really cool and efficient to store data of any type (char, int, double..etc.) what is a hash table?Hash tables are another type of data structure, used to store, manipulate and search data (of any type) in a table format. It is used mainly because of its O(1) time complexity to store and access data. (very efficient and time effective) 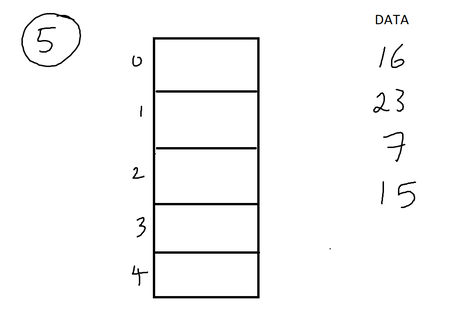 A hash table can have n number of elements, so it can basically be any number. In this case, I chose 5, just to start things easy, but it can also be 100, or 50, 60..etc. So basically the whole idea of a hash table is to store the given data (in this case ints) in every row of the table. In order to decide where to store which number, we derive a hash function. So what is a hash function? How do we decide which one to use? hash functionSo how would you derive your hash function to figure out where to place the keys (a fancy word for data values)? You can basically choose any hash function that works best. For instance, the hash function h(x) = x, basically maps the key to the index with the same value as key. So in that case this would look like: 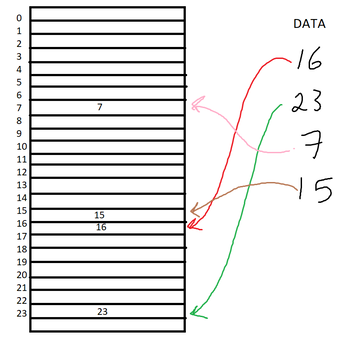 Obviously, there is a problem that arises with this hash function. You would need to allocate numerous spaces in the table, depending on the largest value in your given key data. For instance, if the largest value in the key data is a 23, then you would need to allocate 24 spaces (ranging from 0-23) in your hash table. This will lead to a lot of memory usage, and wasted memory usage for the slots that don't have keys in them. Ok, so then we need to figure out a hash function where you use up less memory but at the same time store the key values efficiently. We can use the modulus (%) function to help us. So, in our 5 slots example, we can set the hash function to be h(x) = x % n, where n is the number of slots, so it would be h(x) = x % 5. So it takes the key, does mod 5 to it, and places the key to the index that matches the result. So if we do 16 % 5 = 1, we get 1 and we place it at index 1. 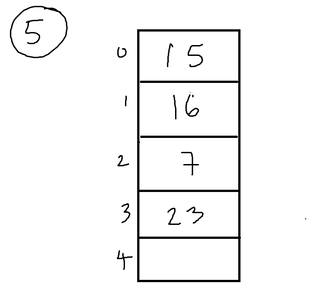 Ok, cool. So this works, and its efficient too since you are using less space for a certain number of elements. But what if I wanted to add another element, such as 33? So first, lets use the hash function on 33. 33 % 5 = 3. So we place it at index 3.....but WAIT. There is already a number at index 3. 23. This is known as collision. When we try to place a number to an index that is already taken by some other number. So how would we tackle such collision? What do we do now? the solution...chainingWhen we encounter such collision, we need to use an effective way to store both of those numbers at index 3 (23 and 33). So we use chaining. This time when creating the hash table, we create an array of pointers. When we insert an element into the hash table, we use the hash function to go the corresponding index, and then make new node so that the pointer in that index points to the node. So, gradually, as more elements are added, we basically make a linked list at every index. 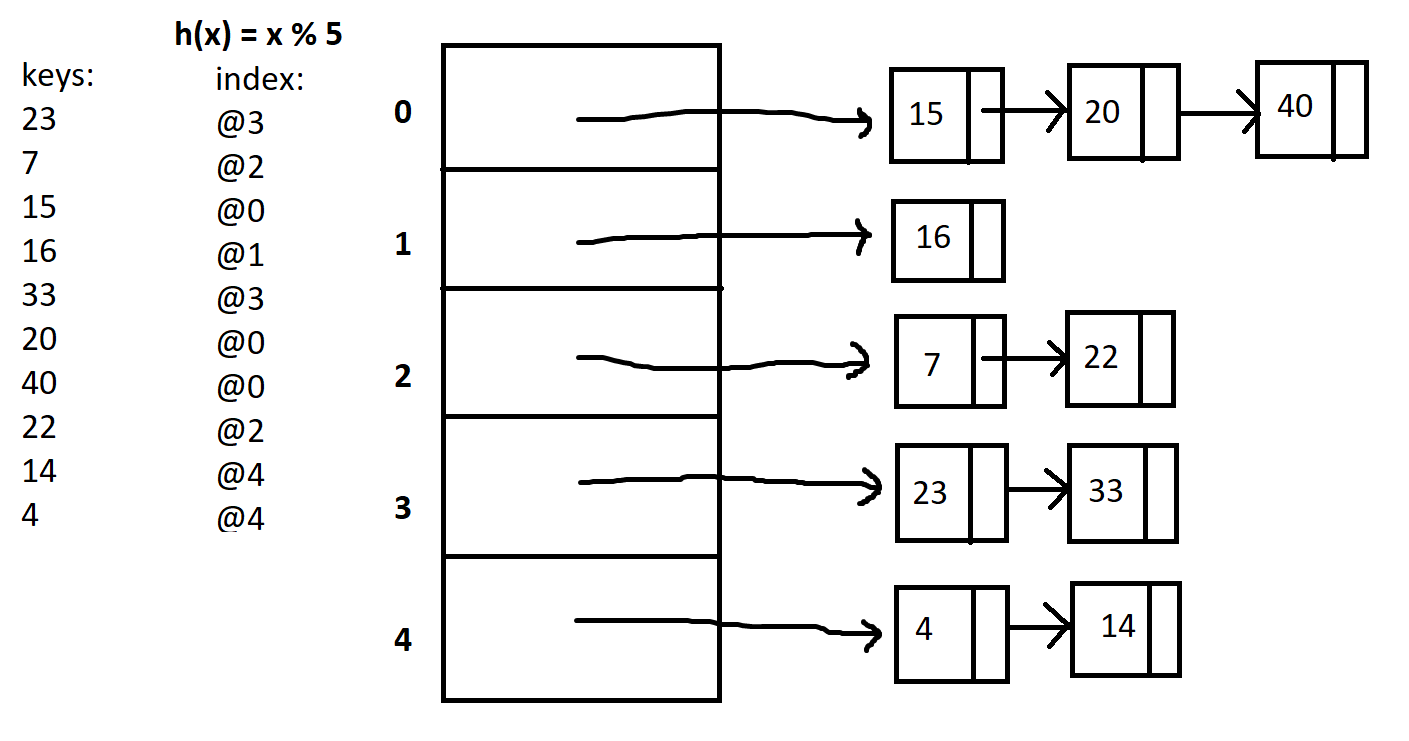 See how nice that looks? This is much more of an organized yet effective way of storing data. You basically use linked lists (another data structure which links one node - or piece of data - to another node until the last one points to NULL) inside of a table of pointers. You can easily access the element by implementing the hash function first, going to the index, and then finding the element. Now lets go to the hard part: converting all of this to C code.
|
Archives
March 2021
Topics
All
|
 RSS Feed
RSS Feed
